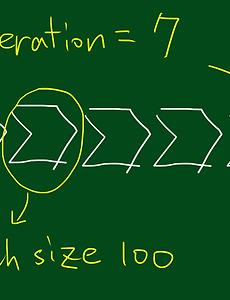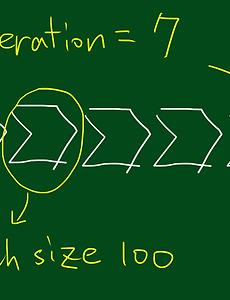 밑바닥부터 시작하는 딥러닝 Chapter4 - 신경망 학습
epoch(에포크) - 전체 트레이닝 셋이 신경망을 통과한 횟수 - 1-epoch는 전체 트레이닝 셋이 하나의 신경망에 적용되어 순전파와 역전파를 통해 신경망을 한 번 통과했다는 것을 의미 - epoch를 높일수록, 다양한 무작위 가중치로 학습을 해보는 것이므로 적합한 파라미터를 찾을 확률이 올라간다. 즉, 손실값이 내려간다. - 지나치게 epoch를 높이게 되면, 그 학습 데이터셋에 과적합(overfitting)되어 다른 데이터에 대해선 제대로 된 예측을 하지 못할 수 있다. 1epoch : [1, 2, 3, 4], [5, 6, 7, 8], [] ...2epoch : [45, 9, 24, 83], [5, 378, 75, 14], [] ...위와 같이 다음 epoch를 돌릴 때 batch의 순서를 섞는 ..
2022. 6. 17.
밑바닥부터 시작하는 딥러닝 Chapter4 - 신경망 학습
epoch(에포크) - 전체 트레이닝 셋이 신경망을 통과한 횟수 - 1-epoch는 전체 트레이닝 셋이 하나의 신경망에 적용되어 순전파와 역전파를 통해 신경망을 한 번 통과했다는 것을 의미 - epoch를 높일수록, 다양한 무작위 가중치로 학습을 해보는 것이므로 적합한 파라미터를 찾을 확률이 올라간다. 즉, 손실값이 내려간다. - 지나치게 epoch를 높이게 되면, 그 학습 데이터셋에 과적합(overfitting)되어 다른 데이터에 대해선 제대로 된 예측을 하지 못할 수 있다. 1epoch : [1, 2, 3, 4], [5, 6, 7, 8], [] ...2epoch : [45, 9, 24, 83], [5, 378, 75, 14], [] ...위와 같이 다음 epoch를 돌릴 때 batch의 순서를 섞는 ..
2022. 6. 17.